TIL 32 : JPA, Spring Data JPA
RDB(Relational Database) : 관계형 데이터베이스는 키와 값들의 간단한 관계를 테이블화 시킨 매우 간단한 원칙의 전산정보 데이터베이스
RDBMS(Relational Database Management System) : 관계형 데이터베이스를 생성하고 수정하고 관리할 수 있는 소프트웨어
패러다임 불일치 문제란?
간단하게, 코드로 DB를 CRUD하려고 하는데
✔️ DB는 “표(table)” 중심
✔️ Java는 “객체(object)” 중심
→ 이 둘은 구조 방식이 달라서 코드랑 DB가 자연스럽게 연결되지 않는 문제가 생김.
이걸 바로 패러다임 불일치(Paradigm Mismatch) 라고 함!
💡 그래서 이걸 해결하려고 나온 게?
✅ JPA (Java Persistence API)
→ 객체와 테이블 사이를 자동으로 연결해주는 기술!
→ Persistence 영어 뜻 검색해보니 고집?이라고 뜨는데 추가로 보니 여기서는 "영속성"이라는 뜻으로 쓰이는 듯
Java의 ORM(Object-Relational Mapping) 기술 표준(인터페이스)

→ ORM : 자바 객체랑 DB 테이블을 자동으로 연결해주는 기술
→ JPA : ORM을 위한 “자바 표준 인터페이스(스펙)”
→ Hibernate : JPA 구현체 중 하나로 가장 많이 쓰이는 구현체, JPA 기능을 실제로 동작하게 해주는 엔진, 거의 모든 스프링 예제에서 사용
→ EclipseLink : JPA 구현체 중 하나로 오라클에서 만든 구현체, JPA 스펙 만든 곳이기도 함
→ DataNucleus : JPA 구현체 중 하나로 범용 ORM (NoSQL도 지원함), 잘 쓰이지 않음 (학습용으로만 가끔 등장)
→ Spring Data JPA : 스프링이 제공하는 JPA 확장 기능, JPA를 더 쉽게 쓰게 해주는 스프링 도구
✅ JPA 성능 최적화 4대 기능 요약
| 기능명 | 한 줄 요약 | 효과 |
| 1차 캐시 | DB 대신 메모리에서 먼저 찾기 | 조회 속도↑, DB 쿼리 줄이기 |
| 쓰기 지연 | INSERT를 모아서 한 번에 보내기 | 쿼리 수↓, 성능 향상 |
| 지연 로딩 | 연관된 데이터는 “나중에” 가져오기 | 필요한 순간에만 쿼리 |
| 즉시 로딩 | 연관된 데이터를 “즉시” 함께 가져오기 | 연관 데이터 함께 필요할 때 유리 |
1️⃣ 1차 캐시 (1st-level cache)
💡 “JPA는 조회한 데이터를 DB 말고 메모리(RAM, 서버 메모리 의미)에도 저장"
User user1 = em.find(User.class, 1L); // DB에서 가져옴
User user2 = em.find(User.class, 1L); // ❌DB 쿼리 안 나감! 메모리에서 꺼냄• 한 트랜잭션 내에서는 같은 id의 엔티티는 무조건 한 번만 조회
• 이걸 1차 캐시라고 함 (영속성 컨텍스트가 가지고 있음)
• JPA의 **1차 캐시(영속성 컨텍스트)**는
→ EntityManager 객체 안에 있음!
→ 즉, JVM 안에 있는 자바 객체의 메모리에 저장 됨.
• ✔️ 트랜잭션이 끝나면 → 1차 캐시는 자동으로 flush & clear됨
✅ 1L은 왜 L을 붙일까?
자바에서 L을 붙이면 → long 타입이라는 뜻
• 1만 쓰면 기본적으로 **int 타입(32비트)**으로 인식
• 근데 @Id로 사용되는 PK는 보통 Long 타입
• 타입을 맞춰주기 위해서 → 1L처럼 long 리터럴을 쓰는 것!
flush & clear 기능
| 용어 | 의미 |
| 영속성 컨텍스트 | JPA가 엔티티를 저장해두는 1차 캐시 |
| flush() | 메모리에 있는 변경 내용을 DB에 반영 |
| clear() | 영속성 컨텍스트(1차 캐시) 초기화 |
2️⃣ 쓰기 지연 (Write-behind / Batching)
💡 em.persist() 했을 때 바로 DB에 INSERT 쿼리 안 날아감
→ commit() 할 때 한꺼번에 날림!
em.persist(user1); // DB에 아직 쿼리 안 나감
em.persist(user2); // 아직 안 나감
em.getTransaction().commit(); // 💥 여기서 INSERT 두 개가 한 번에 실행됨• 쿼리를 모아서 보내니까 네트워크 비용 줄고, 속도 빨라짐
3️⃣ 지연 로딩 (Lazy Loading)
💡 관계된 엔티티는 필요할 때 가져오기
@Entity
class Post {
@ManyToOne(fetch = FetchType.LAZY) // 지연 로딩
private User author;
}Post post = postRepository.findById(1L); // ❌ 아직 author 쿼리 안 날아감
post.getAuthor().getName(); // 💥 여기서 author 쿼리 실행• 불필요한 조인 방지 → 최적의 쿼리 실행 가능
4️⃣ 즉시 로딩 (Eager Loading)
💡 관계된 엔티티를 바로 함께 조회
@ManyToOne(fetch = FetchType.EAGER)
private User author;Post post = postRepository.findById(1L); // 💥 Post + author 조인 쿼리 즉시 실행• 즉시 로딩은 성능 저하를 유발할 수 있음
• 그래서 대부분은 지연 로딩(LAZY) 를 기본으로 설정!
JPA, Spring Data JPA 사용 예시
💥 그냥 JPA (스프링 없이)
→ 직접 EntityManager로 persist, find 등 다 컨트롤해야 함.
✅ EntityManagerFactory란?
💡 EntityManager를 만드는 공장(factory) 객체!
✅ EntityManager란?
✔️ JPA의 핵심 객체
→ DB랑 연결해서 자바 객체(Entity)를 DB에 저장하거나, 꺼내오게 도와주는 관리자
• 저장하고 싶을 때 → em.persist(객체)
• 조회하고 싶을 때 → em.find(클래스, id)
• 삭제하고 싶을 때 → em.remove(객체)
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin(); // 트랜잭션 시작
User user = new User("sun", "1234");
em.persist(user); // INSERT
User found = em.find(User.class, user.getId()); // SELECT
em.getTransaction().commit(); // 트랜잭션 종료• EntityManager는 항상 트랜잭션 안에서 작업해야 함!
• 그래서 항상 begin() → 작업 → commit() 이 순서.
• em.persist()는 메모리에서만 저장해두고 → commit() 할 때 실제로 DB에 INSERT 쿼리가 나감!
왜 Factory에서 Manager를 생성해주는걸까?
1. 성능과 확장성 : factory는 무겁기 때문에 시작 시 한번만 생성 해야함
2. 요청별로 다른 작업 : 여러 사람이 동시에 하나의 객체(EntityManager)에 접근하면 데이터가 엉키거나 오류가 날 위험이 있어서 요청별로 매너지를 생성하여 처리.
🧠 스프링에서는?
Spring Data JPA에서는 자동으로 EntityManagerFactory 만들어주고,
필요할 때마다 EntityManager도 자동 주입해줌.
🌱 Spring Data JPA
public interface UserRepository extends JpaRepository<User, Long> {
Optional<User> findByEmail(String email);
}userRepository.save(user); // 자동 persist
userRepository.findById(1L); // 자동 select
hibernate.dialect
JPA는 SQL을 직접 작성하지 않아도 되게 해주는 기술이지만 DB마다 SQL 문법이 조금씩 다름.
예를 들어
• MySQL은 LIMIT 1
• Oracle은 ROWNUM = 1
• PostgreSQL은 FETCH FIRST 1 ROWS ONLY
Dialect란?
방언이라는 뜻 (지역마다 말투가 다르듯이!)
• DB마다 SQL 문법이 **조금씩 다른 “말투”**를 가지고 있음.
• Hibernate가 그걸 이해해서 맞춤 SQL로 바꿔주는 것
영속성 컨텍스트(PersistenceContext)
솔직히 강의 개어렵, 그림 봐도 이해 안가는데 일단 기록용으로 저장 😒
> 그냥 위에 JPA 설명할때 사용하는 이유 중 1차 캐시를 의미하는 것으로 이해함.
1차 캐시
엔티티를 영속성 컨텍스트에 저장할 때 생성되는 메모리 내 캐시이다. 엔티티는 먼저 1차 캐시에 저장되고 이후 같은 엔티티를 요청하면 DB를 조회하지 않고 1차 캐시에서 데이터를 반환하여 성능을 높일 수 있다.
동일성 보장
동일한 트랜잭션 안에서 특정 엔티티를 여러 번 조회해도 항상 같은 객체 인스턴스를 반환한다. 영속성 컨텍스트는 1차 캐시를 사용하여 같은 엔티티를 중복 조회해도 동일한 객체를 참조하게 하여 일관성을 유지한다.
쓰기 지연(Transactional write-behind)엔티티 객체의 변경 사항을 DB에 바로 반영하지 않고 트랜잭션이 커밋될 때 한 번에 반영하는 방식으로 이를 통해 성능을 최적화하고 트랜잭션 내에서의 불필요한 DB 쓰기 작업을 최소화한다.
변경 감지(Dirty Checking)
영속성 컨텍스트가 엔티티의 초기 상태를 저장하고 트랜잭션 커밋 시점에 현재 상태와 비교해 변경 사항이 있는지 확인하는 기능이다.
flush영속성 컨텍스트의 변경 내용을 데이터베이스에 반영하는 기능으로, 변경된 엔티티 정보를 SQL로 변환해 데이터베이스에 동기화한다. 트랜잭션 커밋 시 자동으로 실행되지만 특정 시점에 데이터베이스 반영이 필요할 때 수동으로 호출할 수도 있다.
1차 캐시

데이터베이스에 저장된 데이터 조회
- 1차 캐시는 동일한 트랜잭션 안에서만 사용이 가능하다.
- 요청이 들어오고 트랜잭션이 종료되면 영속성 컨텍스트는 삭제된다.


Entity Manager 를 통해서 영속성 컨텍스트에 접근한다.
- EntityManager.persist(entity);
Entity(객체)를 영속성 컨텍스트에 영속(저장)한다.

동일성 보장

쓰기 지연
- flush 되면서 SQL 쿼리 실행
- 트랜잭션이 Commit 되면서 실제 DB에 반영

변경 감지

flush
트랜잭션이 Commit 되는 시점에 자동으로 호출된다.
em.flush() 를 통해 수동으로 호출할 수 있다.
Entity
데이터베이스에서 Entity란 저장할 수 있는 데이터의 집합을 의미한다.
JPA에서 Entity란 데이터베이스의 테이블을 나타내는 클래스를 의미한다.

Entity 생명주기
✅ JPA 엔티티 생명주기 4단계 요약
| 상태 | 설명 | JPA관리 | DB 반영 |
| 🟥 비영속 (new) | 그냥 자바 객체 | ❌ NO | ❌ NO |
| 🟩 영속 (managed) | 영속성 컨텍스트에 저장됨 | ✅ YES | ❌ (commit 또는 flush 해야 DB 반영됨) |
| 🟨 준영속 (detached) | 관리하다가 끊김 | ❌ NO | ❌ NO |
| ⛔ 삭제 (removed) | 삭제 예약 상태 | ✅ YES | ❌ (commit 시 DELETE 됨) |
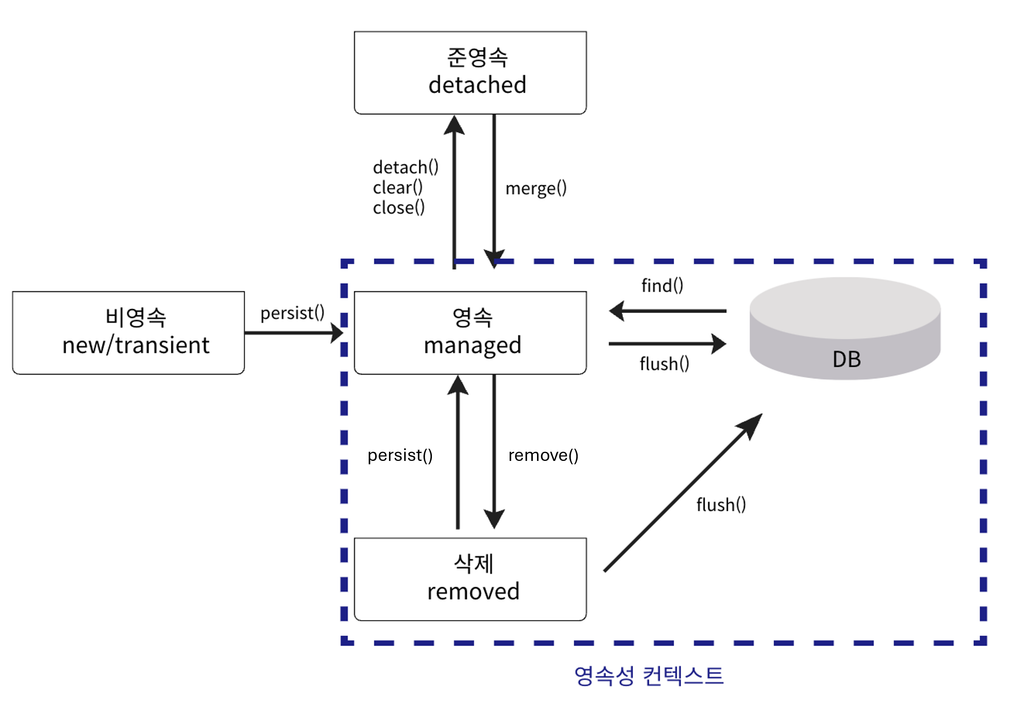
- 비영속(new/transient)
- 영속성 컨텍스트가 모르는 새로운 상태
- 데이터베이스와 전혀 연관이 없는 객체
- 영속(managed)
- 영속성 컨텍스트에 저장되고 관리되고 있는 상태
- 데이터베이스와 동기화되는 상태
- 준영속(detached)
- detach는 영속성 컨텍스트에서 지운다, 준영속 상태로 만듦
- 영속성 컨텍스트가 제공하는 기능을 사용하지 못한다.
- 준영속 상태로 만드는 방법
- em.detach() : 특정 Entity만 준영속 상태로 변경한다.
- em.clear() : 영속성 컨텍스트를 초기화 한다.
- em.close() : 영속성 컨텍스트를 종료한다.
- 삭제(removed)
- 영속성 컨텍스트에 의해 삭제로 표시된 상태
- 트랜잭션이 끝나면 데이터베이스에서 제거
@Entity
클래스에 @Entity가 있다면 JPA가 관리하는 Entity로 만들어진다.
- JPA를 사용하여 객체를 테이블과 매핑할 때 사용한다.(필수)
- PK 값이 필수이다.(@Id 사용)
- 기본 생성자가 필수이다.
- final, enum, interface, inner 클래스에는 사용할 수 없다.
- 필드에 final 키워드를 사용할 수 없다.
- 속성
- @Entity(name = "Tutor")
- Entity 이름 지정
- 기본 값은 클래스 이름과 같다.(생략 가능 ⬇)
- 혼동을 방지하기 위해 기본 값을 사용(생략)하면 된다.
- @Entity(name = "Tutor")
@Id
strategy 속성
- GenerationType
- IDENTITY : MySQL, PostgreSQL에서 사용, 데이터베이스가 PK 자동 생성
- SEQUENCE : Oracle에서 사용, @SequenceGenerator 와 함께 사용
- TABLE : 키 생성용 테이블을 사용, @TableGenerator 와 함께 사용
- AUTO : dialect에 따라 자동 지정, 기본값
기본적으로 AUTO_INCREMENT는 DB에 INSERT SQL이 실행된 이후 PK를 알 수 있지만 IDENTITY 전략은 트랜잭션 Commit 후가 아닌 em.persist() 시점에 즉시 INSERT SQL을 실행하여 PK를 바로 조회할 수 있다.
Default 설정인 GenerationType.AUTO는 버전에 따라 선택되는 전략이 달라질 수 있으니 꼭 직접 DB에 맞는 전략을 지정하여 사용해야 한다.
@Entity ➡️ @Column
제약 조건 설정
@Column(unique = true, length = 20, nullable = false)- unique : 유니크, 기본값 false
- nullable : 필수 여부, 기본값 true
- length : 길이
필드 맵핑
| 종류 | 설명 |
| @Column | DB 컬럼 매핑에 사용 |
| @Temporal | 날짜 타입 |
| @Enumerated | enum 타입 기본 설정인 ORDINAL을 사용하면 0, 1 과 같은 순서가 저장된다. |
| @Transient | DB 컬럼과 매핑하지 않을 때 사용 |
| @Lob | tinytext |
@Entity
@Table(name = "board")
public class Board {
@Id
private Long id;
// @Column을 사용하지 않아도 자동으로 매핑된다.
private Integer view;
// 객체 필드 이름과 DB 이름을 다르게 설정할 수 있다.
@Column(name = "title")
private String bigTitle;
// DB에는 기본적으로 enum이 없다.
@Enumerated(EnumType.STRING)
private BoardType boardType;
// VARCHAR()를 넘어서는 큰 용량의 문자열을 저장할 수 있다.
@Column(columnDefinition = "longtext")
private String contents;
// 날짜 타입 DATE, TIME, TIMESTAMP를 사용할 수 있다.
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Transient
private int count;
public Board() {
}
}
@Column 속성
| 속성 | 설명 | Default |
| name | 객체 필드와 매핑할 테이블의 컬럼 이름 | 객체 필드 이름 |
| nullable | DDL 생성 시 null 값의 허용 여부 설정 | true(허용) |
| unique | DDL 생성 시 하나의 컬럼에 유니크 제약조건을 설정 | |
| columnDefinition | DDL 생성 시 데이터베이스 컬럼 정보를 직접 설정할 수 있다. | |
| length | DDL 생성 시 문자 길이 제약조건 설정 단, String만 사용 가능 | 255 |
| insertable | 설정된 컬럼의 INSERT 가능 여부 | true |
| updatable | 설정된 컬럼의 UPDATE 가능 여부 | true |
@Enumerated
- EnumType.ORDINAL : 순서 저장 ⬅️ Default 값
- EnumType.STRING : 이름 저장
기본 설정인 ORDINAL을 사용하면 0, 1 과 같은 순서가 저장된다.
EnumType.ORDINAL을 사용하면 Enum 값이 추가될 때 마다 순서가 바뀌기 때문에 실제로 사용하지 않는다.

@Temporal
- TemporalType.DATE : 2025-01-01
- TemporalType.TIME : 12:00:00
- TemporalType.TIMESTAMP : 2025-01-01 12:00:00
- MySQL에서 TIMESTAMP는 DATETIME 이다.
- 최신 버전의 Hibernate에서 LocalDate, LocalDateTime는 @Temporal이 생략이 가능하다.
@Table
내 고향 서울엔~~~ 아직 눈이 와요~~ 눈비비며 겨울잠을 이겼더니~~~
내 고향 서울엔~~~ 아직 눈이 와요~~ 쌓여도 난 그대로 둘 거예요~~~
속성
- name
- Entity와 매핑할 테이블 이름을 지정
- 기본 값은 Entity 이름(Tutor)을 사용
- 보통 명시 해줌, Why? : DB는 소문자만 사용하는데 클래스는 대문자로 시작해서 지정해준다~~
- catalog
- 데이터베이스 catalog 매핑
- schema
- 데이터베이스 schema 매핑
- uniqueConstraints
- DDL 생성 시 유니크 제약 조건 설정
hibernate.hbm2ddl.auto
JPA는 Application 로딩 시점에 DDL을 자동으로 생성하는 기능을 지원한다. 방언(dialect)을 사용하여 Entity Mapping만 하여도 데이터베이스에 맞는 적절한 DDL이 생성된다.
hibernate.hbm2ddl.auto는 테이블을 자동으로 어떻게 생성하고 관리할지 설정하는 Hibernate의 핵심 설정 값
댔고~~~~ DDL 자동 생성 설정하는 곳?이다.

| 값 | 설명 | 사용 예 |
| create | 기존 테이블을 삭제(DROP) 후 다시 생성(CREATE)한다. | 테스트용, 초기 개발용 |
| create-drop | DROP 후 CREATE 하고 종료시점에 테이블을 삭제(DROP)한다. 테스트 시 사용 | H2 메모리 DB 테스트용 |
| update | 변경된 사항만 DDL에 반영한다. | 개발 초기 (운영 ❌) |
| validate | Entity와 테이블이 정상적으로 매핑 되었는지 확인한다. 실패 시 예외 발생 | 운영 시 권장 (수정 ❌) |
| none | 속성을 사용하지 않는다. | 운영 배포 시 권장 ✅ |
추가 : jdbc.batch_size : 해당 크기에 따라서 한 번에 insert 되는 rows가 결정
연관관계 Mapping (Association Mapping)
객체끼리의 관계를 **DB 테이블의 외래 키(FK)**로 바꿔주는 JPA의 기능
단반향(One Way)

💬 A → B로만 관계가 있음 (B는 A를 모름)
- Tutor의 FK와 Company의 PK를 @JoinColumn으로 매핑한다.
- Java Collection을 사용하는 것처럼 tutor.getCompany() 를 사용할 수 있다.
@Entity
@Table(name = "tutor")
public class Tutor {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// N:1 단방향 연관관계 설정
@ManyToOne
@JoinColumn(name = "company_id")
private Company company;
// 기본 생성자, getter/setter
}@Entity
@Table(name = "company")
public class Company {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// 기본 생성자, getter/setter
}// Company 생성 및 persist
Company company = new Company("sparta");
em.persist(company);
// Tutor 생성, setCompany, persist
Tutor tutor = new Tutor("wonuk");
tutor.setCompany(company);
em.persist(tutor);
// IDENTITY 전략을 사용하면 persist()이후 PK를 바로 조회할 수 있다.
Tutor findTutor = em.find(Tutor.class, tutor.getId());
// 조회한 Tutor의 Company 조회
Company findCompany = findTutor.getCompany();양방향(Two Way)
💬 A ↔ B 서로 관계를 알고 있음
@Entity
@Table(name = "tutor")
public class Tutor {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// N:1 단방향 연관관계 설정
@ManyToOne
@JoinColumn(name = "company_id")
private Company company;
// 기본 생성자, getter/setter
}@Entity
@Table(name = "company")
public class Company {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
// null을 방지하기 위해 ArrayList로 초기화 한다.(관례)
@OneToMany(mappedBy = "company")
private List<Tutor> tutors = new ArrayList<>();
// 기본 생성자, getter/setter
}// Company 생성 및 persist
Company company = new Company("sparta");
em.persist(company);
// Tutor 생성, setCompany, persist
Tutor tutor = new Tutor("wonuk");
tutor.setCompany(company);
em.persist(tutor);
// IDENTITY 전략을 사용하면 persist()이후 PK를 바로 조회할 수 있다.
Tutor findTutor = em.find(Tutor.class, tutor.getId());
// 조회한 Tutor의 Company 조회
Company findCompany = findTutor.getCompany();
// Company에 속한 Tutor List 조회
List<Tutor> tutors = findCompany.getTutors();
양방향 연관관계 규칙
- 두개의 Entity 중 하나를 연관관계의 주인으로 설정 해야한다.
- 연관관계의 주인은 mappedBy 속성을 사용하지 않는다.
- 연관관계의 주인이 아니라면 mappedBy 속성을 사용한다.
- 연관관계의 주인이 아니라면 조회만 가능하다.
- 연관관계의 주인만 외래 키를 관리(등록, 수정)할 수 있다.
연관관계의 주인 선정 기준
- 항상 FK가 있는 곳을 연관관계의 주인으로 지정한다.
- Company가 주인인 경우
- Company를 수정할 때 Tutor를 Update하는 SQL이 실행
- 두번의 SQL이 실행되어야 한다. 혼동되기 쉽다.
Spring Data JPA
기본적으로 필요한 EntityManagerFactory와 TransactionManager를 자동으로 설정하고 데이터베이스 관련 설정을 application.properties 파일에서 간단히 지정할 수 있게 해준다.
Spring Boot 에서 JPA를 사용하기 위해서는 build.gradle에 의존성 추가가 필요하다.
- spring-boot-starter-data-jpa
- 필요한 JPA 설정과 Entity 관리를 자동으로 해준다.
자동으로 내부에서 EntityManagerFactory 를 하나만 생성해서 관리(싱글톤)한다.
- 자동으로 Bean으로 등록된다.
- 직접 만들지 않아도 된다.
- 직접 연결을 close() 하지 않아도 된다.
- application.properties 에 설정된 DB 정보로 생성된다.
@PersistenceContext를 통해 자동으로 생성된 EntityManager를 주입받아 사용할 수 있다.
- JPA 추상화 Repository 제공
- CrudRepository, JpaRepository 인터페이스를 제공한다.
- SQL이나 EntityManager를 직접 호출하지 않아도 기본적인 CRUD 기능을 손쉽게 구현할 수 있다.
- JPA 구현체와 통합
- 일반적으로 Hibernate를 통해 자동으로 SQL이 생성된다.
- QueryMethods
- Method 이름만으로 SQL을 자동으로 생성한다.
- @Query 를 사용하여 JPQL 또는 Native Query를 정의할 수 있다.
- 복잡한 SQL을 직접 구현할 때 사용
- 트랜잭션 관리와 LazyLoading
- 트랜잭션 기능을 Spring과 통합하여 제공한다.
- 연관된 Entity를 필요할 때 로딩하는 지연로딩 기능을 지원한다.
JPA 사용
public class MemberRepository {
@PersistenceContext
private EntityManager em;
public void save(Member member) {
em.persist(member);
}
public Member findById(Long id) {
return em.find(Member.class, id);
}
public List<Member> findAll() {
return em.createQuery("SELECT * FROM member", Member.class).getResultList();
}
public void delete(Member member) {
em.remove(member);
}
}
Spring Data JPA 사용
public interface MemberRepository extends JpaRepository<Member, Long> {
// JPA Query Methods
public Member findById(Long id);
}EntityManager 는 동시성 문제 방지를 위해 싱글톤으로 등록되지 않는다. Spring Boot는 프록시(가짜 객체)를 싱글톤으로 등록해 요청마다 별도의 EntityManager 인스턴스를 제공하여 각 요청은 독립적으로 EntityManager 를 사용해 안전하게 데이터베이스 작업을 처리할 수 있게 된다.
SimpleJpaRepository
Spring Data JPA의 기본 Repository 구현체로 JpaRepository 인터페이스의 기본 메서드들을 실제로 수행하는 클래스이다. 내부적으로 EntityManager를 사용하여 JPA Entity를 DB에 CRUD 방식으로 저장하고 관리하는 기능을 제공한다.
사용방법
- Repository를 interface로 선언한다.
- JpaRepository<"@Entity 클래스", "@Id 데이터 타입"> 상속
public interface MemberRepository extends JpaRepository<Member, Long> {
}- 내부동작
- Spring이 실행되면서 JpaRepository 인터페이스를 상속받은 인터페이스가 있다면, 해당 인터페이스의 정보를 토대로 SimpleJpaRepository 를 생성하고 Bean으로 등록한다.
- 인터페이스의 구현 클래스를 직접 만들지 않아도 JpaRepository 의 기능을 사용할 수 있다.
- 개발자가 직접 SimpleJpaRepository를 사용하거나 참조할 필요는 없다.
- save() : 대상 Entity를 DB 테이블에 저장한다.
- findAll() : Entity에 해당하는 테이블의 모든 데이터를 조회한다.
- delete() : 대상 Entity를 데이터베이스에서 삭제한다.
- 이외에도 수많은 기능(Paging, Sorting 등)이 있다.
Query Methods
Spring Data JPA에서 메서드 이름을 기반으로 데이터베이스 쿼리를 자동 생성하는 기능이다. 직접 SQL을 작성하지 않고도 복잡한 쿼리를 쉽게 수행할 수 있게된다.
- JpaRepository는 findAll(), save()와 같은 기본적인 기능만 제공한다.
- 실제 Application 개발에는 상황에 따라 조건에 맞는 메서드가 필요하다.
- JpaRepository의 제네릭에 선언된 Entity와 매핑되는 테이블의 SQL이 생성된다.
- 개발자가 규칙에 맞게 메서드를 선언하면 SimpleJpaRepository에서 구현된다.
- 해석
- find : Entity에 매핑된 테이블(member)을 조회한다.
- ByName : 조건은 member 테이블의 name 필드이다.
- AndAddress : 또다른 조건은 member 테이블의 address 필드이다.
공식문서
https://docs.spring.io/spring-data/jpa/reference/jpa/query-methods.html
JPA Query Methods :: Spring Data JPA
By default, Spring Data JPA uses position-based parameter binding, as described in all the preceding examples. This makes query methods a little error-prone when refactoring regarding the parameter position. To solve this issue, you can use @Param annotati
docs.spring.io
JPA Auditing
엔티티의 생성 및 수정 시간을 자동으로 관리해주는 기능입니다. 이를 통해 개발자는 엔티티가 언제 생성되고 수정되었는지를 자동으로 추적할 수 있다.
- @EnableJpaAuditing
- JPA Auditing 기능을 활성화 한다.
- 일반적으로 Spring Boot를 실행하는 Application 클래스 상단에 선언한다.
- @MappedSuperClass
- 해당 어노테이션이 선언된 클래스를 상속받는 Entity에 공통 매핑 정보를 제공한다.
- @EntityListeners(AuditingEntityListener.class)
- Entity를 DB에 적용하기 전, 커스텀 콜백을 요청할 수 있는 어노테이션
- AuditingEntityListener
- Auditing 기능을 사용할 수 있도록 Listener를 설정한다.
- 내부적으로 @PrePersist 을 사용한다.
- @CreateDate
- 생성 시점의 날짜를 자동으로 기록한다.
- @LastModifiedDate
- 수정 시점의 날짜를 자동으로 기록한다.
- @Temporal
- 날짜 타입을 세부적으로 지정한다 (DATE, TIME, TIMESTAMP 등)
- @CreatedBy
- Entity 생성자의 정보를 자동으로 저장한다.
- 생성하는 주체를 지정하기 위해서 AuditorAware<T> 를 지정해야 한다.
- Spring Security에서 다루는 내용
- @LastModifiedBy
- 마지막 수정자의 정보를 자동으로 저장한다.
- 생성하는 주체를 지정하기 위해서 AuditorAware<T> 를 지정해야 한다.
- Spring Security에서 다루는 내용
- Column(updatable = false) : 생성 시간이 수정되지 못하게 설정한다.
@Getter
@MappedSuperclass
@EntityListeners(AuditingEntityListener.class)
public abstract class BaseEntity {
@CreatedDate
@Column(updatable = false)
@Temporal(TemporalType.TIMESTAMP)
private LocalDateTime createdAt;
@LastModifiedDate
@Temporal(TemporalType.TIMESTAMP)
private LocalDateTime modifiedAt;
}@Entity
public class User extends BaseEntity{
@Id
private Long id;
private String name;
}- createdAt, modifedAt 필드를 가지게 된다.
- 상속받는 것만으로 생성, 수정 시간을 자동으로 생성할 수 있다.